The thing is — you don’t actually need them. Quality multilingual (audio, transcript) datasets already exist: FLEURS covers 100+ languages, Common Voice and MLS cover dozens more. The bottleneck isn’t data, it’s the evaluation method. So we built one that works with any (audio, transcript) corpus.
We tested Seamless (Meta), WhisperX, Qwen3-ForcedAligner, and a commercial cloud ASR API on FLEURS across EN / ES / FR / RU.
Method
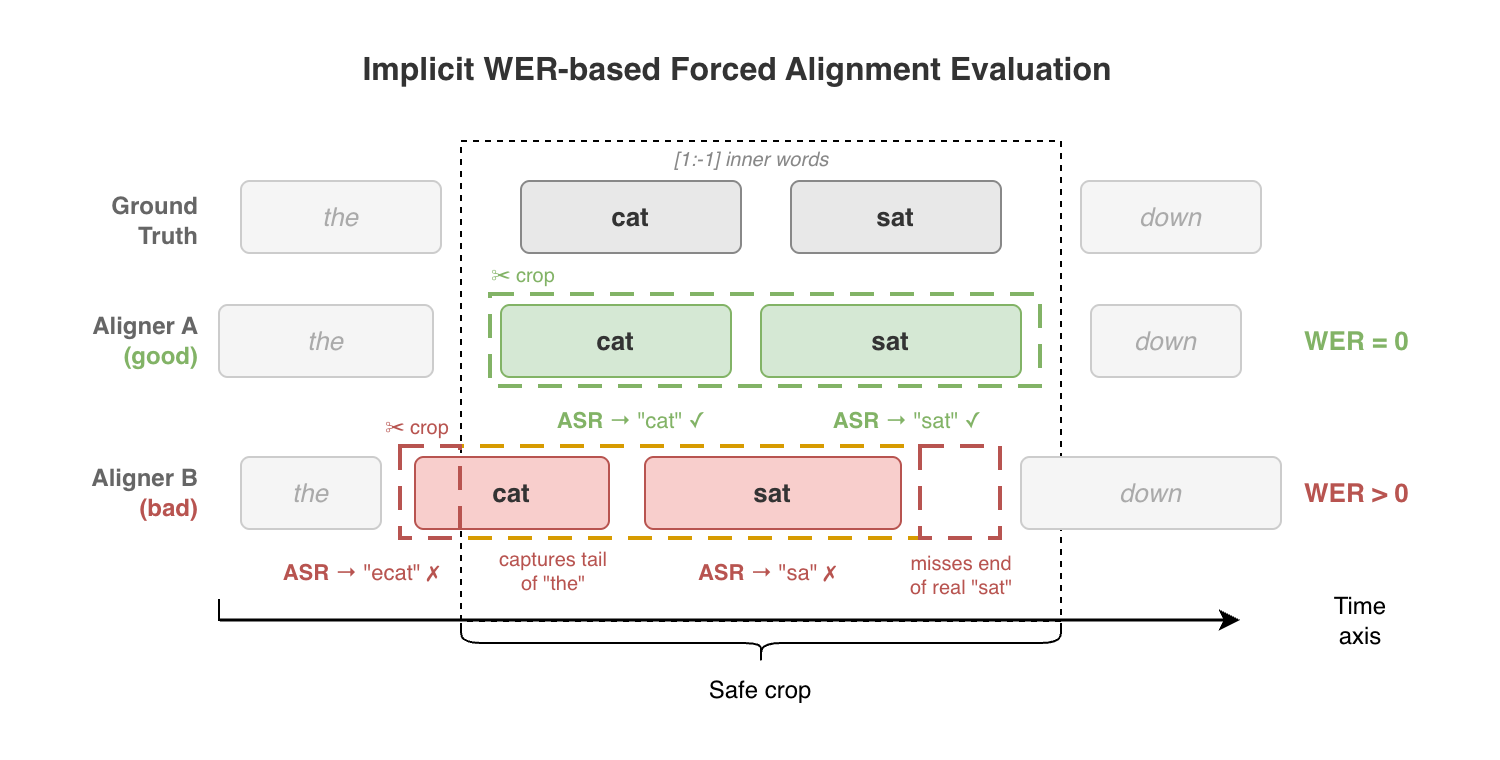
Instead of ground-truth timestamps, we use an implicit WER-based evaluation:
- Run a forced aligner on (audio, transcript) pairs to get word-level timestamps
- Crop audio at the aligned word boundaries
- Re-transcribe each crop with an independent ASR (Whisper large-v3-turbo)
- Compute WER between the crop transcription and the expected text
Better alignment = tighter crops = lower WER. Accurate boundaries mean each crop contains exactly the target word. Misaligned boundaries cut words or bleed neighboring audio, causing transcription errors.
To isolate alignment quality from aligner ASR quality, results are filtered to utterances where all aligners produced perfect transcription reconstruction (strict mode). Inner words only ([1:-1]) are used to avoid edge effects at utterance boundaries.
Aligners
| Aligner | Type | Approach |
|---|---|---|
| Seamless | NAR T2U + unit extraction | Duration prediction with monotonic alignment (RAD-TTS based) |
| Qwen3 | Transformer forced aligner | LLM-based slot-filling with discrete timestamp prediction |
| WhisperX | CTC-based | Word boundaries extracted from wav2vec2 CTC emissions |
| Cloud ASR | Cloud API | Commercial transcription API with alignment output |
Results
Dataset: FLEURS test split, strict filtering (intersection of utterances with perfect transcription across all aligners), inner words only.
Mean WER by language
| Aligner | EN | ES | FR | RU |
|---|---|---|---|---|
| Seamless | 0.067 | 0.030 | 0.102 | 0.055 |
| Qwen3 | 0.072 | 0.039 | 0.104 | 0.059 |
| Cloud ASR | 0.091 | 0.038 | 0.098 | 0.050 |
| WhisperX | 0.082 | 0.065 | 0.155 | 0.133 |
Lower is better. Bold = best per language.
Takeaways
Seamless is the most consistent performer overall. Duration prediction with monotonic alignment produces stable word boundaries across languages — the model explicitly learns duration, not just token occurrence.
WhisperX struggles on FR and RU. CTC emissions predict token occurrence in sequence, not precise duration. The spiked posteriors make boundary extraction unreliable, especially for morphologically rich languages.
Qwen3-ForcedAligner had high expectations as an LLM-based aligner, but on this benchmark the advantage over Seamless isn’t visible. Worth watching, not a clear winner yet.
Cloud ASR edges out on FR and RU, but margins are small and Seamless wins on average. Worth noting: alignment comes bundled with their transcription response, so we filtered to utterances where the API’s recognition exactly matched FLEURS ground truth. This reduced the test set and may slightly favor it.
Seamless’ practical limitation: fixed set of 38 languages. If yours isn’t covered, you’re back to CTC-based approaches.
For our production pipeline at Palabra AI, Seamless is the current choice.
Implementation
The benchmark infrastructure — alignment wrappers, crop logic, WER computation, multi-GPU extraction — was built with Claude Code. Each aligner is wrapped behind a unified interface, and the full pipeline (align → crop → transcribe → score) runs with a couple of bash scripts.
Code & benchmark: github.com/PalabraAI/forced-aligners-bench
]]>